[논문리뷰] Exploring Enhanced Contextual Information for Video-Level Object Tracking. AAAI'25
2025. 1. 13. 07:00ㆍObject Tracking
- LaSOT benchmark 상위권 논문들을 읽어보는 중입니다. 앞서 리뷰한 SAMURAI과 DAM4SAM은 memory management 개선만으로 추가적인 학습 없이 SAM 2의 성능을 올릴 수 있음을 보여주는 연구였는데요, 이번에 리뷰할 MCITrack은 Mamba를 활용한 새로운 구조의 모델을 제안합니다.

Problem
- 기존 visual trackers [1, 2, 3, 4, 5]는 target의 initial appearance만 고려했기 때문에 video sequence 동안 물체의 외형 변화에 취약했습니다. (a) 성능 향상을 위해 dynamic template을 사용하여 target의 appearance의 변화를 고려할 수 있었지만, context를 고려하는 것은 아니였습니다 [6, 7, 8]. 이런 유형의 연구들은 image-level trackers로 분류됩니다.
- 최근들어서는 video-level trackers 연구가 많이 이루어지고 있습니다. (b) 특히, extra tokens를 사용해 contextual information을 전파하는 연구들이 많습니다 [9, 10, 11, 12, 13]. 하지만 이런 모델들도 그 token의 수가 적어 information loss가 발생하고, rich contextual information을 전파하기엔 어려운 구조입니다.

- Temporal model (e.g., LSTM and state space models)이 이런 contextual information 활용에는 효과적입니다. MCITrack은 state space model의 일종인 Mamba [14]를 활용해 효과적인 contextual information propagation을 달성할 수 있음을 제시합니다.
MCITrack

- Backbone
- Fast-iTPN [15]이 backbone network로 사용됩니다. ViT [16]처럼 Transformer layers로 구성되어 있지만, "narrower and deeper" 하기 때문에 shallow-level details와 deeper semantic를 동시에 담고있는 feature를 얻을 수 있습니다.
- 전체 sequence를 담은 video clip \(\mathbf{V} \in \mathbb{R}^{N \times 3 \times H_z \times W_z}\) 와 target을 찾을 search region \(\mathbf{X} \in \mathbb{R}^{3 \times H_x \times W_x}\) 가 입력으로 주어집니다.
- 두 입력은 stride of 4와 convolution을 거쳐 각각 1/16 크기의 patches \(\mathbf{F}_{\mathbf{v}} \in \mathbb{R}^{N \times C \times \frac{H_z}{16} \times \frac{W_z}{16}}\)와 \(\mathbf{F}_{\mathbf{x}} \in \mathbb{R}^{C \times \frac{H_x}{16} \times \frac{W_x}{16}}\) 로 encoding 되고, spatial dimension을 따라 concatenate되어 \(L\)개의 feature vectors \(\mathbf{F}_{\mathbf{vx}} \in \mathbb{R}^{C \times L}\) 가 됩니다.
- 이후 \(\mathbf{F}_{\mathbf{vx}}\)는 \(n (=4)\) 개의 Transformer blocks를 거치는데요, 각 block마다 Contextual Information Fusion (CIF) Module의 CIF block이 pair를 이룹니다.
- Contextual Information Fusion Module
- CIF block은 각 Transformer block에 contextual information을 보강해주는 역할을 합니다. 그림에서도 알 수 있듯, Transformer block에 입력이 들어가기 전 contextual information을 추가해주고, block의 출력을 다시 입력받아 context를 update 합니다.
- CIF block은 하나의 mamba layer와 두 개의 cross-attention layers로 구성됩니다. In-attention layer는 contextual information을 backbone에, out-attention layer는 backbone features를 CIF block에 전달하는 역할을 합니다.
- 그림으로는 무엇이 query이고 key이고 value인지 헷갈리는데요, 이럴 땐 수식으로 보는것이 더 쉽고 정확합니다. 이때, \(\mathbf{F}_{c}^{0}\)은 search region features일 것입니다.

- 참고로 mamba layer는 아래와 같이 구성됩니다.

- Head
- Classification heads와 regression heads로 구성됩니다 [17]. Convolution layers로 구성된 세 개의 sub-networks의 출력은 각각 다음과 같습니다:
- Classification score \(S \in \mathbb{R}^{1 \times \frac{H_x}{16} \times \frac{W_x}{16}}\)
- Bounding box size \(B \in \mathbb{R}^{2 \times \frac{H_x}{16} \times \frac{W_x}{16}}\)
- Offset size \(O \in \mathbb{R}^{2 \times \frac{H_x}{16} \times \frac{W_x}{16}}\)
- Classification heads와 regression heads로 구성됩니다 [17]. Convolution layers로 구성된 세 개의 sub-networks의 출력은 각각 다음과 같습니다:
- Loss Function
- Classification loss, focal loss, regression loss (L1 & GIoU)의 세가지 종류로 image-level loss를 계산합니다. Video-level loss는 image-level의 단순 합으로 구해집니다.
Experiments
- 5 Model Variants
- Speed는 Intel Core i7-8700K CPU @ 3.7GHz, 47GB RAM, 2080 Ti GPU가 달린 머신에서 측정되었습니다.

- Training Datasets
- 5 종류의 datasets (LaSOT, GOT-10k, TrackingNet, COCO, VastTrack)으로 학습되었습니다.
- Inference
- 5-frames 짜리 video clip을 사용합니다. 학습시에도 마찬가지입니다.
- 5 frames를 넘어가는 video에 대한 tracking이 가능하게 만들기 위해 memory bank를 도입한 것 같은데요, 논문에 기술된 아래 설명외에는 자세한 설명이 없어 이해하기가 힘드네요. SAM 2 처럼 output mask를 출력한 후, 별도로 관리되는 memory bank를 도입한듯 합니다. 코드를 살펴봐야 정확히 이해할 수 있을 것 같습니다.
- Update interval \(T\)에 다다르면 memory bank에 저장된 frames로 video clip을 대체합니다. Tracking이 실패했을 때 hidden state를 update 하는건 contextual information을 오염시키므로, classification score가 threshold를 넘겼을 때에만 update 합니다.
Experiments
- Quantitative results on LaSOT, LaSOT_ext, TrackingNet, GOT-10k, TNL2K, NFS, and UAV123. GOT-10k 데이터셋에 대해서는 fair comparison을 위해 GOT-10k에서만 학습한 모델의 성능이 report 되었습니다. LaSOT_ext를 제외하고선 다양한 데이터셋과 모델 크기에 대해 꽤나 좋은 성능을 보임을 알 수 있습니다. 비교적 최근에 나온 (그래서 다른 모델은 학습에 사용하지 못했을 것 같은) VastTrack을 학습에 사용한 것이 좋은 성능에 크게 기여하지 않았나 의심하고 있었는데요, GOT-10k에서의 우수한 결과가 의심을 조금은 해소해주네요.


- Ablation Study of the CIF Module on LaSOT. In & out cross attention이 성능에 유의미한 영향을 줍니다. 그런데 CIF block의 수, hidden states의 수에도 성능이 생각보다는 크게 영향을 받습니다.

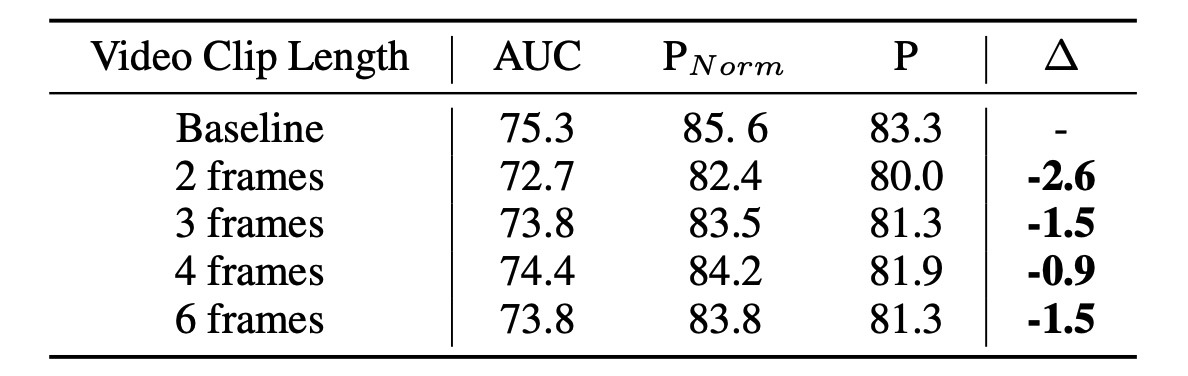
- Ablation Study of the Video Clip Length on LaSOT. Frame 수가 적으면 appearance information이 부족해 성능이 감소하지만, 많아도 학습에 부담이 됩니다. 그래도 6 frames 정도를 부담이라고 하기에는 좀 아쉽습니다.
- Ablation Study of Contextual Information Propagation Methods on LaSOT. Propagation을 아예 하지 않은 경우 ("Wo CI"), 기존의 propagation 방법을 사용한 경우 ("Extra Token"), 그냥 직전 features를 넣어주는 경우 ("Previous Features"), 그리고 Mamba 대신 LSTM을 사용한 경우 ("LSTM")의 비교 결과를 보여줍니다. Mamba가 contextual information 전달에 적합한 구조임을 잘 보여주는 실험입니다.

- 정성적인 결과는 찾아봐도 report 해둔게 없네요. 다양한 벤치마크에서의 정량적 성능이 우수해 좋은 성능이 기대되기는 합니다. 코드는 공개되어 있으니 궁금하면 직접 돌려봐야겠습니다.
References
- Learning Discriminative Model Prediction for Tracking. ICCV'19
- Siamese Box Adaptive Network for Visual Tracking. CVPR'20
- Correlation-Aware Deep Tracking. CVPR'22
- Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework. ECCV'22
- Visual Prompt Multi-Modal Tracking. CVPR'23
- Learning Spatio-Temporal Transformer for Visual Tracking. ICCV'21
- Transforming Model Prediction for Tracking. CVPR'22
- High-Performance Transformer Tracking. T-PAMI'23
- ODTrack: Online Dense Temporal Token Learning for Visual Tracking. AAAI'24
- Explicit Visual Prompts for Visual Object Tracking. AAAI'24
- Spatial-Temporal Initialization Dilemma: Towards Realistic Visual Tracking. VI'24
- ARTrackV2: Prompting Autoregressive Tracker Where to Look and How to Describe. CVPR'24
- Autoregressive Queries for Adaptive Tracking with Spatio-Temporal Transformers. CVPR'24
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces. COLM'24
- Fast-iTPN: Integrally Pre-Trained Transformer Pyramid Network with Token Migration. T-PAMI'24
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR'20
- Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework. ECCV'22