Video Segmentation
[논문 리뷰] Universal Instance Perception as Object Discovery and Retrieval, CVPR'23
hobin-e
2023. 10. 29. 23:30
Motivation
- Instance perception task는 "영상에서 prompt에 의해 특정되는 object를 찾는 task"이다.
- 10종류의 instance perception tasks는 데이터셋이 각각 만들어져 있다 보니 연구도 제각각 이루어지고 있다.
- Object Detection
- Instance Segmentation
- Multiple Object Tracking (MOT)
- Multi-Object Tracking and Segmentation (MOTS)
- Video Instance Segmentation (VIS)
- Referring Expression Comprehension (REC)
- Referring Expression Segmentation (RES)
- Referring Video Object Segmentation (R-VOS)
- Single Object Tracking (SOT)
- Video Object Segmentation (VOS)
- Instance perception task는 time, reference, format에 따라 각기 다른 task로 나눌 수 있다.
- time (영상의 길이): 1 frame (image), n frames (video)
- reference (prompt의 종류): category names, language expressions, and target annotations
- format (출력의 형식): coarse (box) and fine (mask)
- 3D 좌표축에 뿌려보면 더 직관적이다.

- 모든 instance perception tasks를 모두 다룰 수 있는 UNINEXT (UNiversal Instance perception model of the NEXT generation)을 제안함으로써
- 10가지 task 각각을 위해 만들어진 데이터셋을 모두 활용할 수 있고,
- 여러 task를 동시에 다룰 수 있는 parameter & computation efficient model을 학습할 수 있다.
Method

Prompt Generation
- Reference를 encoding 해 prompt features \(F_p\) 를 뽑는 모듈.
- Category names: 모든 category name을 concat 해서 문장 형태로 만들고 (e.g.,
person,giraffe→person. giraffe), BERT [1]에 태운다. - Language expressions: 이미 문장 형태이니 그대로 BERT에 태운다.
- Target annotations는 조금 복잡하다.
- Annotation 주변도 보기 위해, annotation의 중심을 기준으로 가로세로 2배 크기의 patch를 뜯어오고 (
HxWx3), - Annotation 내부임을 표시하는 binary mask channel을 추가하고 (
HxWx4), - CNN을 태워 hierarchical features를 뽑고, upsample to 32x32 -> sum -> flatten을 차례로 통과시킨다.
- Annotation 주변도 보기 위해, annotation의 중심을 기준으로 가로세로 2배 크기의 patch를 뜯어오고 (
- Category names: 모든 category name을 concat 해서 문장 형태로 만들고 (e.g.,
- 복잡하게 썼지만 pseudo-code로 보면 간단하다.

- Prompt features \(F_p\)의 dim은 \(\mathbb{R}^{L \times d}\)로, sequence length \(L\)은 category 수, 단어 수에 따라 달라지며 target annotation의 경우 \(L=1024\) 이다.
Image Prompt Feature Fusion
- 입력 영상으로부터 visual features를 뽑고, prompt features $F_p$와 fusion 하는 모듈.
- CNN으로 입력 영상의 hierarchical features \(F_v\) 를 뽑고, bi-directional cross-attention module을 이용해 prompt features \(F_p\)와 fusion 한다.
- 이런 건 수식으로 보는 게 간단하다.

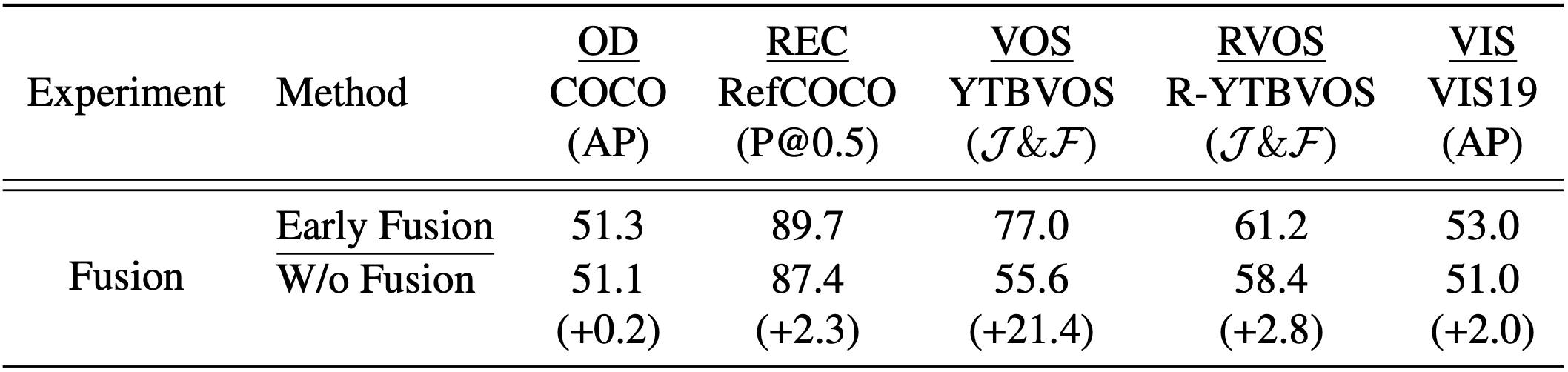
- Prompt의 형태가 복잡할수록 fusion이 성능에 미치는 영향이 크다 (OD & VIS < REC & RVOS < VOS).
Object Discovery and Retrieval
- Hierarchical prompt-aware visual features \(F_{v}^{'}\) 와 prompt embeddings \(F_{p}^{'}\)을 입력받아 instance perception output을 출력하는 모듈.
- Deformable-DETR [2] 구조를 가져다 썼다.
- Encoder
- Hierarchical prompt-aware visual features \(F_{v}^{'}\)를 Multi-scale Deformable Self-Attention [2] 모듈로 encoding 하여 enhanced visual features를 생성한다.
- 추가로, auxiliary prediction head [2] 모듈로부터 top-N initial reference points를 생성한다.
- Decoder
- 먼저, instance embedding \(F_{ins}\) 을 생성하고 시작한다.
- Enhanced visual features로부터 object queries를 이용해 instance embedding을 추출해 올 것이다.
- 기존 연구에서 보여 왔듯이 [3, 4, 5, 6], object queries를 만드는 방법이 성능에 적지 않은 영향을 미치기 때문에 두 가지 방법을 비교해 본다.
- Static queries: Fixed queries (
torch.nn.Embedding). - Dynamic queries: Prompt-based queries (enhanced visual features를 global pooling)
- Static queries: Fixed queries (
- Dynamic을 사용하는 경우 VIS에 유독 큰 성능 drop이 있었기 때문에, static queries를 사용했다.

- 이제 Instance embedding \(F_{ins}\) 을 입력으로 하는 3종류의 prediction heads가 붙는다.
- Instance head: boxes와 masks의 형태로 proposals를 출력한다.
- Embedding head: current instance embeddings와 previous instance embeddings 사이의 contrastive learning [7]을 통해, 다른 시점의 같은 instance 간의 association을 돕는 역할을 한다.

- Retrieval head: Instance head가 출력한 proposals 중, prompt가 가리키는 proposal을 가져온다. 간단히 Instance embeddings와 prompt features 간 dot product를 similarity function으로 사용했다.

- 먼저, instance embedding \(F_{ins}\) 을 생성하고 시작한다.
- Encoder
Training
- 3 stages로 나누어 학습한다.
- Stage 1) General perception pretraining
- Dataset: Object365
- Object365에는 mask annotation이 없기 때문에, BoxInst [8]가 제안한 auxiliary loss로 mask branch를 학습한다.
- Stage 2) Image-level joint training
- Datasets: COCO, RefCOCO, RefCOCO+, RefCOCOg
- Stage 3) Video-level joint training
- Datasets
- Pseudo videos generated from image datasets to prevent catastrophic forgetting: COCO, RefCOCO, RefCOCO+, RefCOCOg
- SOT & VOS: GOT-10K, LaSOT, TrackingNet, Youtube-VOS
- MOT & VIS: BDD100K, VIS19, OVIS
- R-VOS: Ref-Youtube-VOS
- Embedding head는 stage 3에서 처음으로 학습된다.
- Datasets
- Stage 1) General perception pretraining
Experiments
Quantitative
- 10개의 tasks를 다루다 보니 성능을 측정한 public benchmark datasets의 개수가 20개나 된다.

- 모두 SoTA 성능이라 넘어가려고 했는데, VOS task에서 특이한 점을 발견했다.
- Memory를 사용한 모델과 그렇지 않은 모델을 구분해서 성능을 report 하고 있는데, memory 사용 유무에 따라 성능 차이가 꽤 난다.
- Non-memory의 best가 memory의 worst에 미치지 못하는 수준이다.
- Non-memory model은 (1) error propagation 걱정이 없고, (2) memory consumption이 일정하고, (3) 어떤 길이의 비디오도 memory 걱정 없이 처리 가능하다는 장점이 있다고 하는데, 성능이 우선이라면 VOS task에 한해서는 memory model을 사용하는 것이 지금으로서는 좋을 듯하다.
- Multi-task learning이 single-task learning보다 성능이 떨어지는 경우도 종종 있는데, UNINEXT framework에서는 다양한 tasks의 성능이 모두 오른다.
- Target tasks와 큰 관련성이 없는 source tasks가 섞여 있을 때 negative transfer가 발생하는데 [9], 모두 instance perception tasks로 구성되었기 때문에 negative transfer가 발생하지 않은 듯하다.
- 10개의 tasks를 모두 비교하지 않고 5개만 비교한 것은 아쉬운 점이다.

Qualitative
- Prompt: category names
- Prompt: language expressions
- Prompt: target annotations
- Occlusion에 강인한 것이 인상적이다.
Remarks
- VIS/MOTS 모델의 아쉬운 language understanding 및 interaction 능력과 VOS/RVOS 모델의 아쉬운 visual understanding 능력이 보완된 모델을 학습할 수 있는 framework.
- Instance perception tasks 간의 강한 연관성으로 인해 negative transfer 없이 multi-task learning 시너지를 낼 수 있음.
- 코드는 제공하고 있으나 video tasks에 대한 demo scripts를 제공하지 않는 것이 아쉬움.
References
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NACCL-HLT'19
- Deformable DETR: Deformable Transformers for End-to-End Object Detection, ICLR’20
- Trackformer: Multi-Object Tracking with Transformers, CVPR'22
- End-to-end Video Instance Segmentation with Transformers, CVPR'21
- Language as Queries for Referring Video Object Segmentation, CVPR'22
- DINO: DETR with Improved Denoising Anchor Boxes for End-to-end Object Detection, ICLR'23
- In Defense of Online Models for Video Instance Segmentation, ECCV’22
- BoxInst: High-performance instance segmentation with box annotations, CVPR’21
- Identification of Negative Transfers in Multitask Learning Using Surrogate Models, TMLR'23