VLM
[논문리뷰] VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding. arXiv'2501
hobin-e
2025. 3. 17. 07:00
VideoLLaMA는 버전 1 (23년 5월), 버전 2 (24년 6월)에 이어 Alibaba에서 꾸준히 업데이트하고 있는 VLM 입니다. 25년 1월에 버전 3가 공개되었는데요, 이번 글에서는 VideoLLaMA3를 다뤄봅니다.
Introduction
- VideoLLaMA3의 구조입니다. 일반적인 VLM처럼 pre-trainined LLM을 골자로 하여, query가 encoding된 text token 뒤에 video가 encoding된 vision token이 추가로 붙게됩니다. Pre-trained LLM은 Qwen-2.5 [1]를 이용했으며, pre-trained visual encoder는 SigLIP [2]을 사용합니다 (참고로 2B는 SigLIP을, 7B는 pretrained 2B의 visual encoder를 사용합니다).

- 입력 데이터는 아래와 같은 형식입니다.

- VideoLLaMA3는 vision-centric training paradigm과 framework design을 강조하고 있습니다.
- 그렇지만 massive video-text datasets를 구축하기는 현실적으로 어려움을 지적하며, large-scale, high-quality image-text datasets를 충분히 활용함으로써 모델의 video understanding 능력을 끌어올릴 수 있음을 보여줍니다.
- Image-text datasets와 video-text datasets를 4개의 training stages에 어떻게 적용했는지, dynamic resolution을 어떻게 처리했고 video의 인접한 frames에서 발생하는 information redundancy는 어떻게 처리했는지 살펴보겠습니다.
Vision-Centric Paradigm
- 학습은 Vision Encoder Adaptation, Video-Language Alignment, Multi-task Fine-tuning, Video-centric Fine-tuning의 4 stages로 구성됩니다. 각 stage에서 사용되는 datasets의 종류도 아래 그림에서 확인할 수 있습니다. 각 stage에서 사용된 구체적인 data mixture는 논문에서 확인하실 수 있습니다. Stage 3부터는 공개되지 않은 in-house data도 사용하는 것을 알 수 있습니다.
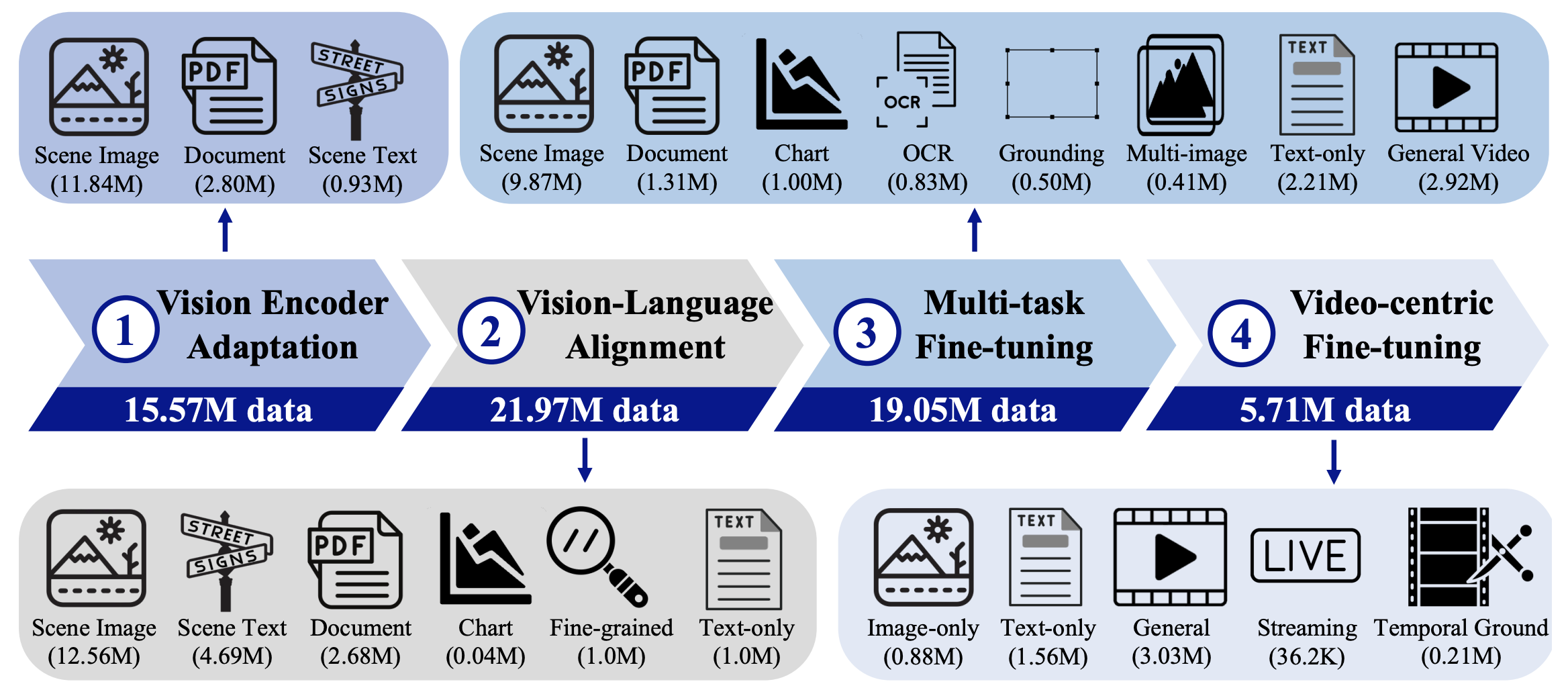
1. Vision Encoder Adaptation
- 이 stage에서는 visual encoder만 학습됩니다.
- 두 가지 역할을 합니다.
- Aligning feature space with the pre-trained LLM
- Kakao Brain의 COYO-700M [3]를 필터링하고 re-caption한 VL3-Syn7M dataset을 구축해 사용했습니다.
- High-quality dataset을 위해
- 적절한 aspect ratio를 가진 이미지만 남기고,
- 일정 수준 이상의 aesthetic score를 가진 이미지만 남기고,
- descriptive and interpretable (BLIP2 caption과 image간의 CLIP similarity가 일정 수준 이상인) 이미지만 남기고,
- diversity를 가지도록 이미지를 선별하고 (CLIP features로 kNN 한 다음, 각 cluster에서 fixed number만 sampling),
- 필터링 된 이미지에 대해 InternVL2-8B와 26B를 돌려 짧고 자세한 caption을 얻어 VL3-Syn7M-short와 VL3-Syn7M-detailed를 구축합니다.
- Adapting fixed to dynamic resolutions
- 다양한 크기의 image와 video를 입력으로 받기 위해 AnyResolution Vision Tokenization [4]을 약간 개선해 사용합니다.
- AnyRes는 image of dynamic resolution을 patches with fixed resolution으로 처리합니다.

source: https://arxiv.org/pdf/2307.06304
- VideoLLaMA3에서는 patches간의 positional relationship도 고려하기 위해 absolute embedding을 rotary positional embedding [5]으로 교체합니다.
- AnyRes는 image of dynamic resolution을 patches with fixed resolution으로 처리합니다.
- VideoLLaMA3에서 처음 제안하는 것은 아닌 것 같고, Qwen2-VL [6]에 M-RoPE라는 이름으로 이미 적용됐었던 기술인듯 합니다. 지금보니 Qwen 시리즈도 Alibaba의 것이군요.

source: https://arxiv.org/pdf/2409.12191
- 다양한 크기의 image와 video를 입력으로 받기 위해 AnyResolution Vision Tokenization [4]을 약간 개선해 사용합니다.
- Aligning feature space with the pre-trained LLM
2. Vision-Language Alignment
- 이 stage에서는 모든 파라미터가 학습됩니다.
- Detailed image-text data를 이용해 multimodal understanding 능력을 키우는 역할을 합니다.
- Spatial reasoning을 위해 bounding box가 포함된 fine-grained image-text data도 사용되고, language capabilities도 잃지 않기 위해 text-only data도 사용됩니다.
3. Multi-task Fine-tuning
- 이 stage에서는 어떤 파라미터가 학습되는지 논문에 나와있지는 않은 듯 합니다. 다만 코드가 공개되어 있으니 알려면 알수도 있겠습니다.
- Downstream tasks (e.g., interactive question answering)를 위해 fine-tuning 하는 역할을 하는 stage 입니다.
- 이 stage부터는 video data가 사용됩니다. General video caption data가 image understanding capabilities를 키우는데 큰 도움이 된다고 합니다.
- Video가 image에 비해 computation demand가 크다보니, video tokens 수를 줄이기 위한 technique이 도입되었습니다.
- 우선, per-frame 2x2 spatial downsampling으로 context length를 줄입니다. Bilinear interpolation이 사용됩니다.
- Video tokens 수를 더 줄이기 위해 (논문에서는 Differential Frame Pruner라고 부르는) Run-Length Tokenization [7]을 사용합니다. 비디오는 종종 프레임의 일부분만 변하고 나머지 부분은 고정일 때가 있습니다. 시간에 따라 변하지도 않는 부분을 매 프레임마다 token을 사용해가며 encoding하기 아까우니, "어떤 token이 n 프레임 연속 나온다"로 encoding 해버리는 전략입니다.

source: Don't Look Twice: Faster Video Transformers with Run-Length Tokenization. NeurIPS'24 
source: Don't Look Twice: Faster Video Transformers with Run-Length Tokenization. NeurIPS'24
- 이런 technique 덕분에 3분짜리 비디오까지는 1fps로 추출한 프레임을 입력으로 사용합니다.
- 3분보다 짧아도 1fps로 추출해서 사용합니다. 적은 수의 프레임이 들어가는 것이지요.
- 3분이 넘어가는 비디오는 총 프레임수가 180이 되도록 uniform sampling을 합니다.
4. Vision-centric Fine-tuning
- 이 stage에서는 모든 파라미터가 학습됩니다.
- Model의 video understanding과 video question answering capabilities를 키우는 역할을 합니다.
- Stage 3의 general video 뿐만아니라 streaming video와 temporal grounding information이 포함된 video data도 학습에 사용됩니다.
Experiments
Quantitative Results
- 비슷한 체급의 public models와의 비교입니다. 다양한 benchmarks에서 좋은 성능을 보이고 있습니다. 다만 Qwen2.5-VL의 weights를 가져다 썼으면서 Qwen2-VL과만 비교하는건 좀 치사한 것 같습니다.
- Image-based evaluation (2B & 7B)
- Video-based evaluation (2B & 7B)
- Image-based evaluation (2B & 7B)
- 그래서 Qwen2.5-VL [1] paper를 참고해 비교하는 표를 만들어보았습니다. Image-based benchmarks에서는 전반적으로 Qwen2.5-VL이 우세하나, video-based benchmarks에서는 선방하는 결과를 보여줍니다. Video-based application에 적용하고자 한다면 use-case에 따라 적절한 모델을 사용하게 될 것 같습니다.
Qwen2.5-VL
(3B)Qwen2.5-VL
(7B)VideoLLaMA3
(2B)VideoLLaMA3
(7B)Image-based MMMU (val) 53.1 58.6 45.3 48.8 MMMU-Pro 31.56 38.3 28.6 33.6 RealWorldQA 65.4 68.5 67.3 72.7 MathVista (testmini) 62.3 68.2 59.2 67.1 ChartQA (test) 84.0 87.3 79.8 86.3 DocVQA (test) 93.9 95.7 91.9 94.9 InfoVQA (test) 77.1 82.6 69.4 78.9 OCRBench 797 864 779 828 Video-based VideoMME (w/o sub) 61.5 65.1 59.6 66.2 VideoMME (w/ sub) 67.6 71.6 63.4 70.3 MMVU (val) - 50.1 39.9 44.1 MVBench 67.0 69.6 65.5 69.7 EgoSchema (test) 64.8 65.0 58.5 63.3 PerceptionTest (test) 66.9 70.5 68.0 72.8 MLVU 68.2 70.2 65.4 73.0 LongVideoBench (val) 54.2 56.0 57.1 59.8 LVBench 43.3 45.3 41.6 45.3 TempCompass 64.4 71.7 63.4 68.1 Charades-STA 38.8 43.6 55.5 60.7 - Vision Encoder의 종류에 따른 ablation study도 진행했습니다. 보통 siglip을 사용한다던데 역시 좋긴 한가보네요.





Qualitative Results
- 다양한 datasets로 학습한 모델이니 할 줄 아는게 많은 모델입니다. 전부 가져오는건 의미가 없을 것 같고, video를 입력으로 받는 몇가지 예시만 가져와 보겠습니다.
- Captioning
- QA
- Captioning




References
- Qwen2.5 Technical Report. arxiv'2412
- Sigmoid Loss for Language Image Pre-Training. ICCV'23
- COYO-700M: Image-Text Pair Dataset. https://github.com/kakaobrain/coyo-dataset. 2022
- Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. NeurIPS'23
- RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing'24
- Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv'2409
- Don't Look Twice: Faster Video Transformers with Run-Length Tokenization. NeurIPS'24