Object Tracking
[논문리뷰] A Distractor-Aware Memory for Visual Object Tracking with SAM2. arXiv'2411
hobin-e
2025. 1. 5. 07:00
Problem
- Tracking이 실패하는 주요 원인 중 하나는 distractors 입니다. Distractors를 두 종류로 구분할 수 있습니다.
- External distractors: Target object 주변에 비슷한 물체가 있는 경우
- Internal distractors: Tracked part와 비슷한 target object의 다른 part가 보이게 된 경우
- Distractors에 의한 visual ambiguity를 해소하기 위한 기존의 노력들은 크게 세가지로 나누어집니다.
- 그냥 feature가 discriminative 하도록 잘 학습하기 [1, 2, 3, 4, 5],
- foreground와 background를 명시적으로 구분하는 모듈 추가하기 [6, 7, 8, 9],
- memory 기반으로 past tracked frames와의 pixel association으로 target 위치 찾기 [10, 11, 12].
- 이 중 가장 최근에 등장한 memory-based frameworks는 major benchmarks (VOT2022, VOTS2023, VOTS2024)에서 좋은 성능을 내고있어 주목받고 있습니다.
- 그러다보니 memory bank를 어떻게 잘 구축할 수 있을지 연구가 많이 되고있는 추세인 듯 합니다.
- RMem [12]에서는 지나치게 큰 memory bank가 오히려 visual redundancy를 발생시키며, 이는 cross-attention의 특성상 오히려 성능을 떨어트릴 수 있기 때문에 memory bank의 크기를 most recent frames만 포함하도록 제한할 것을 제안했습니다.
- SAMURAI [15]에서는 memory bank에 tracked part 대신 distractor가 잘못 들어감으로써 error propagation이 되는 것을 주의해야함을 지적하며, memory bank에 들어갈 memory를 선택할 때 target의 motion까지 고려할 것을 제안했습니다.
- 오늘 리뷰할 논문에서도 distractor를 고려한 memory bank 설계를 다룹니다. 기존 SAM 2 [13]의 memory structure를 대부분 유지한 채 distractor를 고려할 수 있는 디자인을 제안합니다.
- 또한, 현존하는 benchmark들이 이제는 쉬워져버린 sequences로 인해 그 점수가 saturate 되고있어, 정작 중요하게 봐야할 challenging sequences에 대한 성능 차이는 부각되지 않음을 주장합니다.
- 이를 위해 기존 benchmarks를 기반으로 만든 distractor-distilled tracking dataset (DiDi)를 제안합니다.
Distractor-Aware Memory
- SAM 2는 latest 6 frames features를 memory bank에 보관했습니다 (left). 본 논문에서 제안하는 Distractor-Aware Memory (DAM)은 SAM 2의 memory bank를 반으로 나누어 target이 잘 나온 frame을 저장하는 Recent Appearance Memory (RAM)과 distractor가 잘 나온 frame을 저장하는 Distractor Resolving Memory (DRM)으로 사용합니다 (right).
- 참고로, DRM에 최초로 feature가 들어오기 전까지는 6개 slots 전체가 RAM으로 사용된다고 합니다.

- RAM management protocol
- RAM은 SAM 2의 memory bank와 비슷한 역할을 하지만 update 정책은 다릅니다. Visual redundancy를 피하기 위해 매번 update 되는 대신 \(\Delta\) (=5) frames 마다 update 됩니다.
- 단, most recent frame feature는 항상 가지고 있고, target이 없을 때에는 (predicted target mask가 없을 경우) update 하지 않습니다.
- DRM management protocol
- DRM도 RAM처럼 target이 있을 때에만 update하고, last update 후 \((\Delta - 1)\) frames 까지는 update 하지 않습니다.
- 이제 어떤 feature를 distractor로 분류해 DRM에 넣을지가 중요한데요, 연구진들은 SAM 2가 실패 (i.e., target 대신 distractor를 track)하기 전 모델이 이미 distractor를 본 경우가 많았다고 합니다. Distractor가 갑자기 나타나기보다는 실패하기 전부터 target 주변에 등장했었고, (3개의) predicted candidate masks 중 하나로 잡혔지만 output으로 선정되지는 않다가, 어느 시점에서는 output으로 선정되어 실패하게 되는 패턴이 많더라는 말입니다.
- 그렇다면 이제는 predicted but unselected candidate masks 중 어떤 mask를 distractor로 정의할 것인지가 중요해졌습니다. 이런 DRM update는 tracking 성능에 큰 영향을 줄 수 있기 때문에 신중하게 이루어져야하고, 그러다보니 꽤나 복잡한 정책을 사용합니다 (hyperparameters에 민감하진 않다고 하고는 있습니다).
- 먼저 distractor를 선정하는 기준입니다. 우선 bounding box 하나는 output mask에 fit 시키고 (A), bounding 하나는 output mask와 alternative mask의 largest connected component의 union에 fit 시킵니다 (B). A와 B의 ratio가 \(\theta_{\textup{anc}} = 0.7\) 미만이면 DRM을 update할 candidate frame이 됩니다.
- 다음은 선정된 distractor를 memory bank에 update하는 기준입니다. 만약 candidate frame의 predicted IoU score가 \(\theta_{\textup{IoU}} = 0.8\)을 초과하고, mask area가 last \(\theta_{M} = 10\) frames의 median area의 \(\theta_{\textup{area}} = 20\%\) 이내라면 tracking이 충분히 안정기에 접어들었다고 보고 DRM update가 이루어집니다.
Distractor-Distilled (DiDi) Dataset
- DiDi dataset은 7개의 major tracking benchmarks (GoT-10k, LaSOT, UTB180, VOT-ST2020, VOT-LT2020, VOT-ST2022, and VOT-LT2022)의 validation과 test sequences를 일부 선별해서 만들어졌습니다.
- 1/3 이상의 frames가 아래의 distractor presence criterion을 통과하는 sequence만 DiDi dataset에 포함됩니다
- Frame의 pixel-wise DINOv2 features를 얻습니다.
- 각 pixel feature에 대해 GT target region features와의 average cosine distance를 계산합니다. 이 수치가 해당 pixel의 distractor score가 됩니다.
- GT target region의 밖과 안에 위치한 pixels 중 distractor score가 average distractor score in GT target region보다 큰 수를 각각 세고, 밖과 안의 비율이 0.5를 초과하면 distractor를 무시못할 정도로 포함하는 frame이라고 생각할 수 있습니다.
- 위의 distractor presence criterion을 이용해 평균 1.5k frames 길이의 180 sequences로 DiDi dataset이 구성되었습니다. 아래는 그 예시 중 일부입니다.

Experiments
- Metrics
- Quality: VOTS [14] tracking quality Q score
- Accuracy: The average IoU between the prediction and ground truth during successful tracking
- Robustness: The portion of successfully tracked frames
- Ablation Study on DiDi dataset.
- \(\textup{PRES}\) (update only when the predicted mask is not empty): Quality and Robustness 상승
- \(\Delta = 5\) (update less frequently): Robustness 상승 (\(\Delta\)를 더 키워도 추가 효과는 없었다고 합니다)
- \(\textup{DRM1}\) (update only during reliable tracking periods): Robustness 상승
- \(\textup{DRM2}\) (update only when the distractor is detected): 성능 하락 (Tracking error가 target을 distractor로 오인하게 만들 수 있기 때문입니다. DRM update가 복잡할 수 밖에 없는 이유가 되겠네요.)
- \(\textup{DRM}_{\textup{tenc}}\) (use temporal encodings in DRM): 성능 하락
- \(\textup{RAM}_{\overline{\textup{last}}}\) (without latest frame): 성능 하락

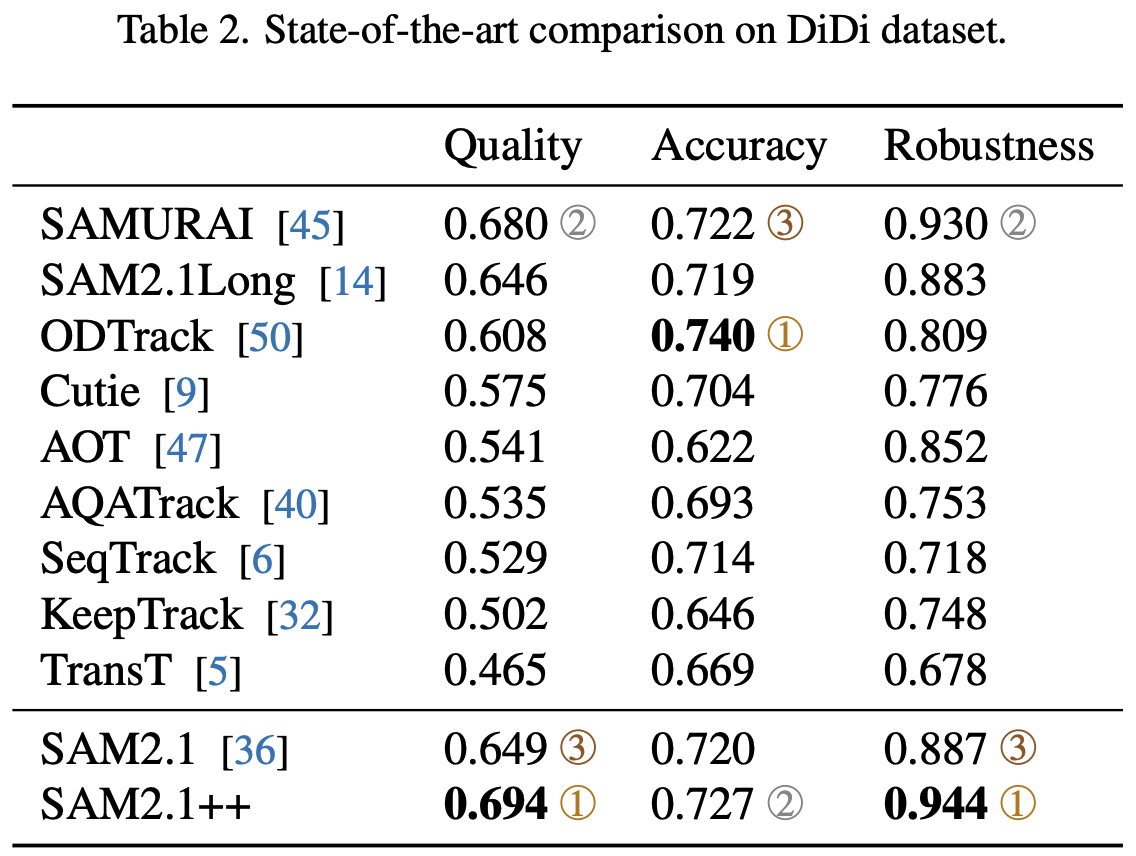
- Quantitative results on DiDi, VOT2020, VOT2022, VOT2024, LaSoT, and GoT10k datasets. Quality와 Robustness scores에서 큰 격차를 보여줍니다. VOT2024에서는 약간 아쉬운 성능인데요, 고성능 모델들은 competition을 위해 만들어진 모델이라 SAM 2보다 큰 backbone을 사용하고 peer review도 받지 않았다고 합니다. 찾아보니 S3-Track은 ICLR'25 리뷰를 받는중이네요. Poster accept이 예상됩니다.




- Quantitative results on DiDi dataset. 그림 위의 그래프는 per-frame overlap을 보여줍니다. 네 개의 sequences 모두가 target과 비슷한 distractors가 많은 challenging scene인데다가, 3번째는 viewpoint change도 있는데 상당히 인상적이네요.

References
- Fully-Convolutional Siamese Networks for Object Tracking. ECCVW'16
- Transformer Tracking. CVPR'21
- Learning Spatio-Temporal Transformer for Visual Tracking. ICCV'21
- MixFormer: End-to-End Tracking with Iterative Mixed Attention. CVPR'22
- SeqTrack: Sequence to Sequence Learning for Visual Object Tracking. CVPR'23
- A Discriminative Single-Shot Segmentation Network for Visual Object Tracking. PAMI'21
- A New Dataset and a Distractor-Aware Architecture for Transparent Object Tracking. IJCV'24
- ODTrack: Online Dense Temporal Token Learning for Visual Tracking. AAAI'24
- Putting the Object Back into Video Object Segmentation. CVPR'24
- Associating Objects with Transformers for Video Object Segmentation. NeurIPS'21
- XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model. ECCV'22
- RMem: Restricted Memory Banks Improve Video Object Segmentation. CVPR'24
- SAM 2: Segment Anything in Images and Videos. ICLR'25
- The First Visual Object Tracking Segmentation VOTS2023 Challenge Results. ICCVW'23
- SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory. arXiv'2411